¶ Premiers pas
C'est parti pour le premier notebook autour de l'IA et du machine learning avec Python!
On va commencer tranquillement par l'installation des principales librairies qui nous serviront dans ce notebook et les suivants.
Ensuite on construira notre premier modèle, très basique, qui sera capable de prédire la cote d'un véhicule selon son age et son kilometrage.
¶ Installations
Si tu lis ce notebook, il y a de forte chances que tu sois compétent techniquement ou alors tu t'appelles Benjamin 😆️.
Je ne vais donc pas m'eterniser sur les prérequis. Sans mystères tu aura besoin de Python et Pip. Plusieurs choix s'offrent à toi:
- installation systeme "classique" via un installateur
- gestionnaire d'environnement virtuel comme Anaconda
- image docker
Perso, j'utilise Anaconda depuis longtemps car je trouve que c'est le meilleur compromis et c'est mieux que la virtualisation par defaut de Python par venv.
¶ Numpy
C'est une référence en Python dés qu'il s'agit de faire des opérations sur tableaux et matrices (ou n'importe quelle liste de manière générale).
pip install numpy
Voici un petit exemple d'opérations une fois installée.
import numpy as np
mat3x3 = np.ones((3, 3))
print("matrice 3 par 3 avec valeurs initialisées à 1\n", mat3x3)
# imaginons qu'on veuille multiplier toutes les valeurs par 5
# en pur python (ou java xD), il faudrait faire des boucles comme des gueux
# avec numpy rien de plus simple
print("matrice multipliée par 5\n", mat3x3 * 5)
# on peut aussi choisir certaines colonnes ou certaines lignes et appliquer une transformation
mat3x3_col = mat3x3.copy()
mat3x3_col[:, 0] = 0
print("copie de la matrice 3 par 3 avec sa 1ere colonne à 0\n", mat3x3_col)
mat3x3_row = mat3x3.copy()
mat3x3_row[0, :] = 0
print("copie de la matrice 3 par 3 avec sa 1ere ligne à 0\n", mat3x3_row)
matrice 3 par 3 avec valeurs initialisées à 1
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
matrice multipliée par 5
[[5. 5. 5.]
[5. 5. 5.]
[5. 5. 5.]]
copie de la matrice 3 par 3 avec sa 1ere colonne à 0
[[0. 1. 1.]
[0. 1. 1.]
[0. 1. 1.]]
copie de la matrice 3 par 3 avec sa 1ere ligne à 0
[[0. 0. 0.]
[1. 1. 1.]
[1. 1. 1.]]
La tel quel ça ne vend pas du rève mais, comme tout l'ecosystem du ML en python est fait avec, il vaut mieux savoir se servir de numpy.
¶ Matplotlib
N'etant pas des robots, on va souvent avoir besoin de visualiser nos données ou des images. Avec ça, on peut faire des graphiques très... bon ok c'est pas forcement beau mais c'est franchement pratique.
pip install matplotlib
On essai ? Juste un petit histogramme que j'ai adapté depuis le site de matplotlib
import matplotlib.pyplot as plt
# make data
np.random.seed(1)
x = np.random.normal(0, 3, 200)
# plot:
fig, ax = plt.subplots()
ax.hist(x, bins=40, linewidth=0.2, edgecolor="white")
ax.set(xlim=(-9, 9), xticks=np.arange(-9, 10),
ylim=(0, 15), yticks=np.linspace(0, 15, 16))
plt.show()
¶ Scikit learn
Tous les algos de base sont dans cette librairie: boosting, PCA, random forest... C'est l'idéal pour commencer à créer ses premiers modeles.
pip install scikit-learn
Elle contient aussi quelques datasets pratique pour faire des PoC. Par exemple
from sklearn.datasets import load_digits
digits = load_digits()
plt.figure()
plt.matshow(digits.images[0], cmap="gray")
plt.show()
<Figure size 640x480 with 0 Axes>
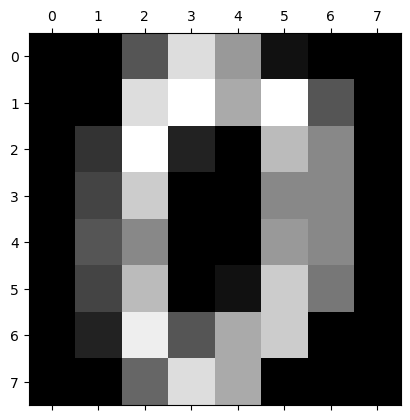
Là, il faut voir un zéro... C'est des datasets de PoC, ils allaient pas mettre des images en résolution 4K !
¶ Pandas
Pandas permet de manipuler et d'analyser des données. C'est utile pour explorer ou retransformer un dataset.
import pandas as pd # c'est la convention pour cette lib xD
patient_dataframe = pd.DataFrame({
'age': [40, 35, 67, 28, 52, 32, 79],
'systolique': [12, 13, 9, 10, 11, 12, 8],
'diastolique': [ 8, 8, 7, 6, 8, 6, 5],
})
patient_dataframe
| age | systolique | diastolique | |
|---|---|---|---|
| 0 | 40 | 12 | 8 |
| 1 | 35 | 13 | 8 |
| 2 | 67 | 9 | 7 |
| 3 | 28 | 10 | 6 |
| 4 | 52 | 11 | 8 |
| 5 | 32 | 12 | 6 |
| 6 | 79 | 8 | 5 |
On peut par exemple choisir de ne garder que les patient de moins de 70 ans et qui ont une pression systolique au moins à 10
patient_dataframe[(patient_dataframe['age'] < 70) * (patient_dataframe['systolique'] >= 10)]
| age | systolique | diastolique | |
|---|---|---|---|
| 0 | 40 | 12 | 8 |
| 1 | 35 | 13 | 8 |
| 3 | 28 | 10 | 6 |
| 4 | 52 | 11 | 8 |
| 5 | 32 | 12 | 6 |
¶ OpenCV
OpenCV, pour open computer vision, est une librairie pour tout ce qui est lié a de l'imagerie.
On peut notamment récupérer le flux vidéo d'une caméra, appliquer des traitements de détection de contour, de la détection de visage...
pip install opencv-python
import cv2
¶ Tensorflow
Plus moyen de faire marche arrière ! Avec celle là, tu rentres dans l'arène et tu vas pouvoir créer des réseaux de neuronnes, rien de moins.
pip install tensorflow
Lui on le testera une autre fois car c'est compliqué de sortir un exemple en quelques lignes.
¶ Premier modèle: cote estimador 🇲🇽️
Pour nos premiers pas, on va s'attaquer à un simple problème de regression linéaire (regression voulant dire qu'on va produire une valeur).
Généralement, pour estimer la valeur ou la cote d'un véhicule, plusieurs parametres sont pris en compte dont l'age et le kilométrage.
La cote baisse plus ou moins proportionnellement avec l'age et le kilometrage cependant ce n'est pas quantifié.
Pour éviter de faire des estimations au doigt mouillé, on pourrait tenter de créer un modèle basé sur des cotes de véhicules d'occasion.
Bon, je n'ai pas ce genre de données sous la main. Ca doit se trouver mais pour la pédagogie du tuto j'ai bricolé un dataset.
On commence par le charger et visualiser les données.
data = pd.read_csv('cote_vehicule.csv')
data
| age | kms | cote | |
|---|---|---|---|
| 0 | 10.538433 | 176887.0 | 0.382765 |
| 1 | 8.748248 | 157537.0 | 0.466219 |
| 2 | 10.964073 | 122280.0 | 0.481338 |
| 3 | 13.431909 | 93481.0 | 0.477241 |
| 4 | 8.477909 | 148309.0 | 0.491434 |
| ... | ... | ... | ... |
| 995 | 8.345553 | 163469.0 | 0.464424 |
| 996 | 14.206244 | 118769.0 | 0.407307 |
| 997 | 10.944773 | 83905.0 | 0.558572 |
| 998 | 7.527738 | 113203.0 | 0.585400 |
| 999 | 10.752328 | 89488.0 | 0.552217 |
1000 rows × 3 columns
plt.figure(figsize=(20, 7))
plt.subplot(1, 2, 1)
plt.plot(data['age'], data['cote'], 'x', markeredgewidth=1)
plt.xlabel('age (annee)')
plt.ylabel('cote (% de la valeur neuve)')
plt.axis((0, 25, 0, 1))
plt.subplot(1, 2, 2)
plt.plot(data['kms'], data['cote'], 'x', markeredgewidth=1)
plt.xlabel('kilometres')
plt.ylabel('cote (% de la valeur neuve)')
plt.axis((0, 300_000, 0, 1))
plt.show()
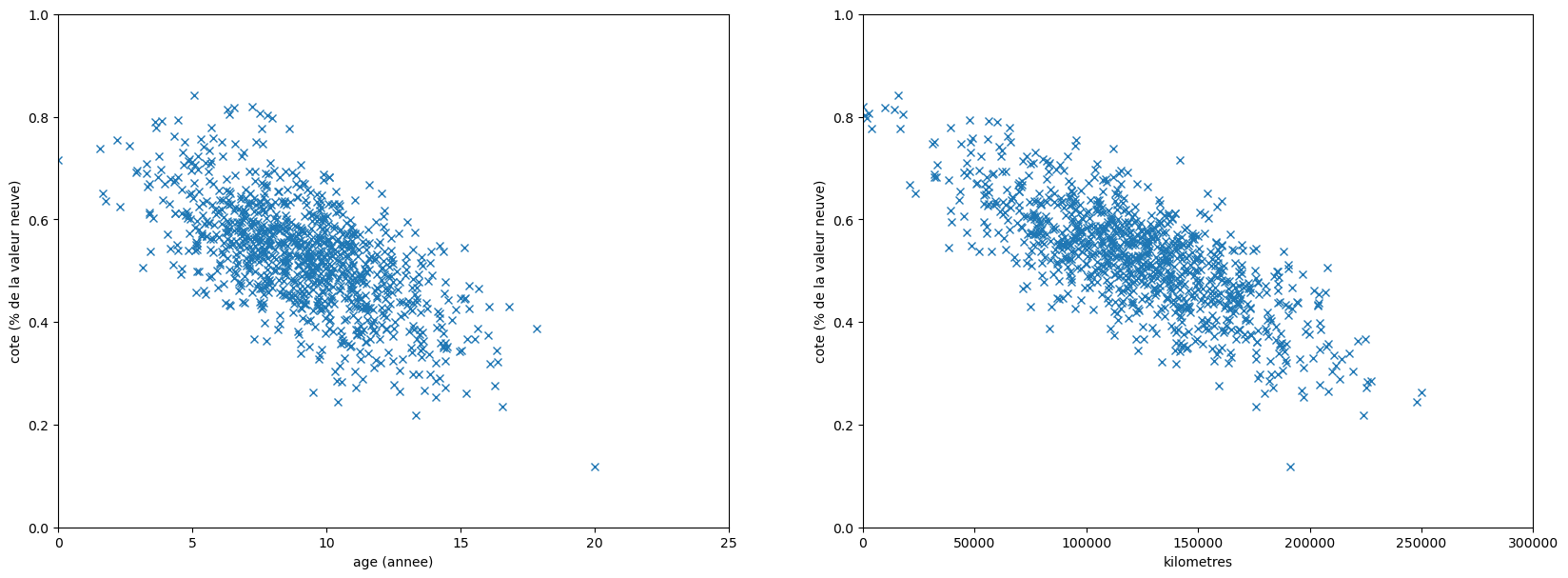
On a obtenu 2 magnifiques nuages de points.
Vu l'etalement, on pourrait probablement tracer une ligne approximative pour chacun des nuages.
Ca serait un début pour établir une "formule magique" de calcul de la decote.
On va le faire avec le paramètre age ce qui permettra de voir ensemble quelques notions de théorie.
¶ Approximation basée sur l'age
C'est le moment où il va falloir se souvenir de 2-3 notions de maths du collège.
Puisqu'on traite un problème de regression linéaire, on est obligé de parler de l'équation théorique des fonctions affines.
Tu sais, celle qui dit f(x) = ax + b = y.
Si on la met en application, qu'est ce qu'on peut en déduire vu le graphique précédent et le contexte des données ? Deux choses:
- la valeur de b doit être 1 ou proche de 1: b c'est la valeur de y lorsque x vaut 0 soit la valeur de la cote quand le véhicule est neuf donc cote à 1
- la valeur de a est négative, probablement entre -0.045 et -0.06: la pente de la fonction qu'on cherche "descend" et semble aller croiser l'axe des absices entre 17.5 et 22.5 soit un coefficient de 1/22.5 = 0.044444444444444446 à 1/17.5 = 0.05714285714285714
On peut deja tester visuellement cette hypothèse en tracant des courbes avec la valeur de b à 1 et plusieurs valeurs de a.
plt.plot(data['age'], data['cote'], 'x', markeredgewidth=1)
for coef_a, color in zip(np.arange(-0.045, -0.065, -0.005), ['red', 'green', 'blue', 'yellow', 'purple']):
plt.axline((0,1), slope=coef_a, color=color, label=f'a = {round(coef_a, ndigits=4)}')
plt.xlabel('age (annee)')
plt.ylabel('cote (% de la valeur neuve)')
plt.axis((0, 25, 0, 1))
plt.legend()
plt.show()
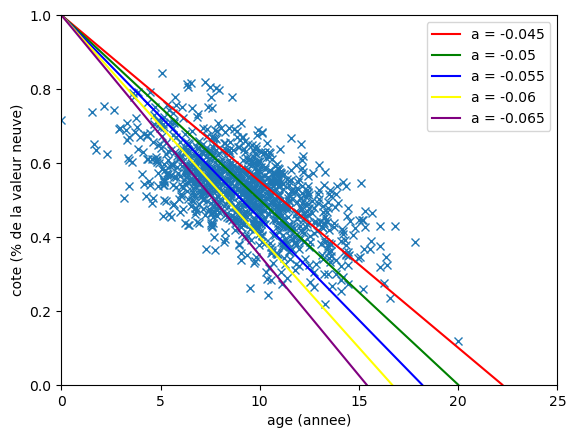
On a le début de quelque chose. Cependant, c'est compliqué d'estimer visuellement quelle courbe est la plus appropriée entre la bleue et la verte.
Aussi, même si le coefficient b trouvait une explication logique, ce n'est pas pour autant qu'il est juste pour représenter les données.
Lui aussi a surement besoin d'être ajusté. On va donc maintenant faire vraiment travailler la machine en faisant un premier algo d'entrainement pour rechercher les meilleurs coefficients.
¶ Algorithme simple
Vu la partie précédente, plutot que de tester une infinité de valeurs pour a et b, on va se limiter a des intervalles crédible.
Pour a, ce sera -0.01 à -0.09. Pour b, ce sera 0.6 à 1.0.
Comme on veut faire un algo simple, on va également fixer le step pour ces intervalles. Si on souhaite tester 100 valeurs dans les intervalles de a et b, alors on a:
def calc_step(min_val, max_val, n_val):
return round((max_val - min_val) / n_val, 6)
min_a = -0.09
max_a = -0.015
step_a = calc_step(min_a, max_a, 100)
min_b = 0.6
max_b = 1.0
step_b = calc_step(min_b, max_b, 100)
step_a, step_b
(0.00075, 0.004)
On pourra donc ecrire la boucle comme cela:
for coef_a in np.arange(min_a, max_a, step_a):
for coef_b in np.arange(min_b, max_b, step_b):
# on teste la fonction avec ces parametres
Là normalement, c'est le moment où tu te dit "diable, on va tester 100x100 valeurs de a et b, comment savoir lesquels sont le meilleures ?"
Et c'est donc le moment de parler du "taux d'erreur" du modèle, qu'on appelle le loss.
Pour résumer assez simplement le loss, on peut dire que c'est une valeur qui reflète l'écart entre les prédictions d'un modèle et des resultats attendus.
Pour une fonction affine y = ax + b, ca revient a dire qu'on va calculer y puis le comparer au y constaté.
Par exemple si on est en train de tester a = -0.050 et b = 1.0:
X = data['age'][0]
y_constate = float(data['cote'][0])
y_modele = float(-0.050 * X + 1.0)
float(X), y_constate, y_modele, y_modele - y_constate
(10.53843278600857,
0.3827650906654272,
0.47307836069957143,
0.09031327003414424)
On voit un ecart de ~0.09 entre le modele et la valeur constatée. Et si on avait pris a = -0.06 et b = 0.9 ?
X = data['age'][0]
y_constate = float(data['cote'][0])
y_modele = float(-0.051 * X + 0.95)
float(X), y_constate, y_modele, y_modele - y_constate
(10.53843278600857,
0.3827650906654272,
0.41253992791356286,
0.029774837248135677)
L'ecart n'est que de ~0.03. Un modèle avec ces valeurs de a et b serait donc jugé meilleur.
Dans la pratique, on utilise pas cette valeur directement, on passe plutot par une fonction qui transforme la mesure brut des écarts. Et comme le monde est bien fait, cela s'appelle la fonction de loss (oui je fais du franglais, et alors ? Kess tu vas faire 🥸️).
Je parlerai probablement dans un autre notebook de ces fonctions mais pour le moment on va utiliser cette fonction qui calcule une moyenne d'ecart:
def calc_loss(y_estime, y_constate):
return np.abs(y_constate - y_estime).mean()
Et maintenant, on le finit cet algo ? Toutes les données vont être stockées dans un tableau. On déduira les meilleurs coefficients en se basant sur le loss le plus bas.
X = data['age']
y_constate = data['cote']
results = []
for coef_a in np.arange(min_a, max_a, step_a):
for coef_b in np.arange(min_b, max_b, step_b):
y_estime = X * coef_a + coef_b
loss = calc_loss(y_constate, y_estime)
results.append((coef_a, coef_b, loss))
results = np.array(results)
index_min_loss = results[:, 2].argmin()
model_a, model_b, min_loss = results[index_min_loss, :]
float(model_a), float(model_b), float(min_loss)
(-0.021749999999999936, 0.7240000000000001, 0.0641719320952113)
Ca y'est ! On a trouvé les meilleures valeurs pour a et b. Ca donne quoi sur un graphique ?
plt.plot(data['age'], data['cote'], 'x', markeredgewidth=1)
plt.axline((0, model_b), slope=model_a, color='red', label='modele')
plt.xlabel('age (annee)')
plt.ylabel('cote (% de la valeur neuve)')
plt.axis((0, 25, 0, 1))
plt.legend()
plt.show()
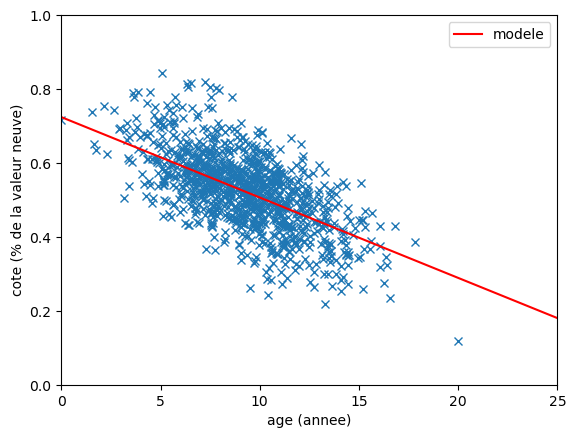
C'est amusant car au final la valeur du modèle pour b n'est pas du tout 1 alors que ça avait tout son sens (en théorie).
Après tu te dis peut être qu'on a juste fait n'importe quoi.
On va donc voir ce qu'aurai trouvé un algo optimisé.
¶ Algorithme avec scikit-learn
Scikit-learn propose plein d'algos pour faire de la regression linéaire. Ils sont optimisés et adaptables peu importe le nombre de parametres.
Comme on traite un problème simple, on va prendre l'algo le plus simple: LinearRegression
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# preparation X et y
X = np.array(data['age']).reshape((1000, 1))
y = data['cote']
# instanciation modele + entrainement
model = LinearRegression()
model.fit(X, y)
float(model.coef_[0]), float(model.intercept_), mean_absolute_error(model.predict(X), y)
(-0.023810080534886934, 0.7435878276326229, 0.06426381270583627)
On tombe bien sur les valeurs approximatives de ce qu'on a trouvé avec notre algo maison. Si on superpose les 2 sur un graphique, on obtient:
plt.plot(data['age'], data['cote'], 'x', markeredgewidth=1)
plt.axline((0, model_b), slope=model_a, color='red', label='modele maison')
plt.axline((0, float(model.intercept_)), slope=float(model.coef_[0]), color='green', label='LinearRegression')
plt.xlabel('age (annee)')
plt.ylabel('cote (% de la valeur neuve)')
plt.axis((0, 25, 0, 1))
plt.legend()
plt.show()
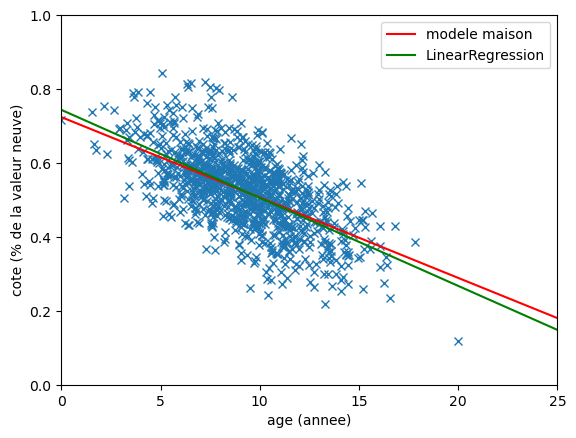
Il y a une différence bien sur, mais c'est quand même pas mal pour quelque chose qu'on a bricolé vite fait et pas optimisé.
Par contre dans les 2 cas, comme on ne prend en compte que l'age du véhicule, pas sur que le modèle soit très pertinent.
Dans la vie, comment on ferait ? On estimerai d'abord en fonction de l'age du vehicule puis on ajusterai en fonction du kilometrage (ou kilometrage puis age, peu importe).
Par exemple, les 2 véhicules suivant présent dans le dataset ont le même age mais des kilometrages différents donc la cote est différente, logique...
data.iloc[[2, 997]] # recuperation des vehicules a l'index 2 et 997
| age | kms | cote | |
|---|---|---|---|
| 2 | 10.964073 | 122280.0 | 0.481338 |
| 997 | 10.944773 | 83905.0 | 0.558572 |
Donc maintenant qu'on a vu comment faire la regression linéaire sur l'age seulement, on va maintenant integrer le 2nd parametre: le kilométrage.
¶ Algorithme avec tous les parametres
En maths, pour ajouter un parametre dans une regression linéaire, il suffit de rajouter la valeur de ce paramètre multiplié par son coefficient.
Concrètement, avant on avait:
cote = coefficient_age x age + biais.
Avec le kilometrage comme 2nd parametre, la formule serait alors:
cote = coefficient_age x age + coefficient_kilometrage x kilometrage + biais.
Le biais dans une regréssion est comme une variable d'ajustement sur l'ensemble de l'équation, c'est pour ça qu'on en rajoute pas à chaque nouveau paramètre.
J'ai affiché la formule mais de toute façon je vais pas refaire l'algo. On va utiliser scikit-learn et refaire un entrainement de modèle mais avec age et kilometrage.
Ca donne:
# preparation des donnees
X = np.array(data[['age', 'kms']]).reshape((1000, 2))
y = data['cote']
# instanciation modele + entrainement
model = LinearRegression()
model.fit(X, y)
model.coef_, float(model.intercept_)
(array([-2.49999994e-02, -2.00000026e-06]), 1.000000014859864)
On peut maintenant tester notre modele sur notre dataset. Au passage on pourra verifier que les 2 vehicules qui avaient le même age mais des kilometrages différents ont bien une cote différente.
df = data.copy()
X = np.array(df[['age', 'kms']]).reshape((-1, 2))
y_constate = df['cote']
y_estime = model.predict(X)
df['cote estimee'] = y_estime
df
| age | kms | cote | cote estimee | |
|---|---|---|---|---|
| 0 | 10.538433 | 176887.0 | 0.382765 | 0.382765 |
| 1 | 8.748248 | 157537.0 | 0.466219 | 0.466220 |
| 2 | 10.964073 | 122280.0 | 0.481338 | 0.481338 |
| 3 | 13.431909 | 93481.0 | 0.477241 | 0.477240 |
| 4 | 8.477909 | 148309.0 | 0.491434 | 0.491434 |
| ... | ... | ... | ... | ... |
| 995 | 8.345553 | 163469.0 | 0.464424 | 0.464423 |
| 996 | 14.206244 | 118769.0 | 0.407307 | 0.407306 |
| 997 | 10.944773 | 83905.0 | 0.558572 | 0.558571 |
| 998 | 7.527738 | 113203.0 | 0.585400 | 0.585401 |
| 999 | 10.752328 | 89488.0 | 0.552217 | 0.552216 |
1000 rows × 4 columns
Et voilà !!! Notre modèle est capable de proposer une cote proche de ce qui est constaté dans le dataset en se basant sur l'age et le kilometrage.
Et pour faire mettre ça en application, si on faisait une petite ihm ?
Genre celle que tu pourrai trouver sur ton site d'achat revente de véhicule d'occasion préféré.
Ca tient en quelques lignes et il n'y a pas besoin d'installer de nouvelles librairies.
import tkinter as tk
import tkinter.ttk as ttk
def hide_calc(*args):
estimation['text'] = ''
def show_calc():
res = model.predict([[age_scale.get(), km_scale.get()]]) * int(valeur_neuve.get())
estimation['text'] = f'Valeur estimée: {round(max(res[0], 0))}€'
window = tk.Tk()
window.title('Totosphère occasions')
window.minsize(640, 480)
titre = tk.Label(window, text='Estime la valeur de ton véhicule')
titre.pack(pady=64)
my_var = tk.StringVar()
tk.Label(window, text='Valeur neuve supérieure à (€)', anchor=tk.W).pack(padx=64, fill=tk.X)
valeur_neuve = ttk.Combobox(window, state='readonly', values=list(range(10_000, 70_000, 5000)), postcommand=hide_calc)
valeur_neuve.bind('<<ComboboxSelected>>', hide_calc)
valeur_neuve.pack(fill=tk.X, padx=64, pady=8)
age_scale = tk.Scale(window, orient=tk.HORIZONTAL, label='Age (années)', from_=0, to=25, tickinterval=5, command=hide_calc)
age_scale.pack(fill=tk.X, padx=64, pady=8)
km_scale = tk.Scale(window, orient=tk.HORIZONTAL, label='Kilometrage', from_=0, to=250_000, tickinterval=50_000, command=hide_calc)
km_scale.pack(fill=tk.X, padx=64, pady=8)
bouton_calc = tk.Button(window, text='Calculer', command=show_calc)
bouton_calc.pack(pady=32)
estimation = tk.Label(window, text='')
estimation.pack(pady=8)
window.mainloop()
¶ Au fait...
Si tu es arrivé jusque là, voici comment j'ai généré le dataset.
np.random.seed(42)
n_samples = 1000
def normalize(arr):
return (arr - arr.min()) / (arr.max() - arr.min())
X1 = normalize(np.random.normal(size=(n_samples, 1)))
X2 = normalize(np.random.normal(size=(n_samples, 1)))
y = 1 + (X1 * -0.5) + (X2 * -0.5)
X1 *= 20
X2 = np.round(X2 * 250_000)
X = np.zeros((n_samples, 2))
X[:, 0:1] = X1
X[:, 1:2] = X2
df = pd.DataFrame({
'age': X[:, 0],
'kms': X[:, 1],
'cote': y[:, 0]
})
df.to_csv('cote_vehicule.csv', index=False)
df
| age | kms | cote | |
|---|---|---|---|
| 0 | 10.538433 | 176887.0 | 0.382765 |
| 1 | 8.748248 | 157537.0 | 0.466219 |
| 2 | 10.964073 | 122280.0 | 0.481338 |
| 3 | 13.431909 | 93481.0 | 0.477241 |
| 4 | 8.477909 | 148309.0 | 0.491434 |
| ... | ... | ... | ... |
| 995 | 8.345553 | 163469.0 | 0.464424 |
| 996 | 14.206244 | 118769.0 | 0.407307 |
| 997 | 10.944773 | 83905.0 | 0.558572 |
| 998 | 7.527738 | 113203.0 | 0.585400 |
| 999 | 10.752328 | 89488.0 | 0.552217 |
1000 rows × 3 columns